如果有关注到brpc最新支持功能的朋友可能已经发现了,brpc在最近支持了redis server端的协议(redis client早已支持),使得brpc server可以接受来自redis client的命令,处理,并返回结果。通过实现brpc提供的命令回调函数,理论上完全可以用brpc来实现出一个redis server,但这并不是支持这个功能的初衷,我们的初衷是通过这个功能来解决SDK灵活性的问题。
什么是SDK灵活性问题?想象这样一个场景:你正在为公司开发一个新系统,目前已经完成系统的基础功能,并对外发布SDK1.0,让公司内不同的团队可以接入你的系统。为了支持更多功能,会对系统进行迭代开发,此时SDK2.0就发布了,这会带来几个问题。
- 问题一:只要基本功能满足要求,不需要用到新功能的用户还会因为稳定性等原因继续使用老的SDK1.0,如果升级是不兼容的,就会使得你需要维护两个版本SDK的系统实现,随着时间的推移维护的版本越来越多。
- 问题二:有些升级仅仅是对服务方有收益,例如为了更好地监控系统节点在客户端的表现,需要在SDK加入了统计上报的功能,这对用户没有直接的提升,用户会继续使用旧版本SDK,导致统计数据收集困难。
- 问题三:当一个新功能需要升级SDK才能用,会引入额外的尝试成本,降低了用户尝试的可能性,导致新功能的推行困难。
- 问题四:某些复杂的SDK还会加入负载均衡、重试、熔断限流等逻辑,如果这些逻辑发生了改变、升级或是bugfix,那么用户也必须显式地升级SDK。
一个灵活的SDK可以在server端升级功能时,客户端的SDK不需要变化就可以直接新功能。redis提供了一种很好的思路,这里首先给不熟悉redis协议的朋友介绍一下它的基本原理。在redis-cli中输入set foo bar后,客户端并不会解析这条命令,而是把用户的输入完整地传给server端,当server解析第一个字符串发现是set后,就会调用对应的处理函数,最后返回结果给客户端。如果延用这种想法,那么就可以在server升级时SDK不需要更改就可以使用新功能。对于用户而言,只要输入最新功能对应的命令即可,没有升级SDK所带来的成本。另外,由于SDK本身并不解析命令,只负责传输,就不存在前文所说的因升级而维护多个SDK系统实现的问题。
为了实现这种想法,brpc需要一套类似的协议,并且SDK需要满足如下几点:
- 具有普遍性,每个语言都有完整且正确的实现
- 具备可维护性,最好不由brpc团队来维护,由第三方/社区来维护
- 具备低学习成本,甚至用户可以一看就会
我们发现redis协议天生就满足上述三点:
- redis client在各个语言中都有比较完整和正确的实现
- redis client由各自语言的社区来维护
- redis是事实上的缓存系统,其开发者对其接口很熟悉,即使不熟悉也可以迅速通过已有的广泛资料学习。
如果brpc能直接支持redis server协议,就能实现上述所讨论的灵活SDK,于是就开始设计和实现,并在最近将一个稳定高效的实现合并到了主干。想尝试这个功能的话已经可以拉最新的master代码,阅读redis.h中的注释文档来构建一个redis server。
在实现中尝试了很多性能优化,这一段来简单说一下。熟悉redis的朋友都知道,消息会在server端按序处理,然后按序返回,而一些二进制协议则没有这种要求,这使得server端可以对这些请求进行并发,一个典型例子是http2.0,序列化的时候会带上一个stream_id,在server处理完消息后会将这个stream_id一并返回,从而使客户端可以找到该rpc的上下文。在实现中遇到的一个主要问题是是否要给redis命令的函数回调支持异步接口,如果支持异步接口,框架层面会递给用户一个回调对象done_closure,在用户做完所有操作后,调用done_closure.Run()就可以了,这种写法的好处是server端的消息处理可以是并发的,对消息不需要严格按序处理的场景可以受益,但由于用户可能随时调用done_closure.Run(),而客户端又要求消息按序返回,框架层面需要提供一种队列机制,后面到达的请求如果先处理好了,就需要等前面的请求处理好了发送出去后,才能发送出去。这种方法虽然灵活性很好,提供了异步接口可以并发,但是框架需要额外的维护成本,在实测中,性能并不是很好。第二版本放弃了异步接口,强制要求所有的消息需要顺序执行,实测中表现非常好,在绝大多数的场景单链接上只有一条消息,这种方式是可以接受的。另外考虑到现实中导致并发处理的往往是batch命令,例如在redis中多条命令同时到达server,针对这种场景,做了一个优化:递给用户一个bool变量表示是否是一批中的最后一个,用户根据这个变量来缓存消息(对应bool值为false)或是批量处理消息(对应bool值为true)。我们在开发中还进行了大量编码上的讨论,由于篇幅限制,更详细的可以看[1]。
听起来好像很完美了,客户端发送任意命令,服务端根据命令解析。然而实际场景中会遇到几个问题:
- 由社区/官方维护的redis client一般没有重试功能,更别说根据业务返回的结果进行按序重试了,同时也缺少了一些高级的功能,例如熔断、限流、不同的负载均衡策略等。
- 已经开发完成的legacy系统一般通过http/h2+pb/json对外提供服务,是不可能为了支持这个功能而用brpc重写的。 计算机科学中遇到的所有问题都可通过增加一层抽象来解决(但抽象不是越多越好,一个好设计是没有多余抽象的,只留下必须的抽象)。为了解决上述问题,可以增加一个brpc redis proxy来加一层抽象,在这个proxy中实现负载均衡、容错等功能,并把请求翻译成系统本身的SDK命令,下图是一个高度抽象的架构图。
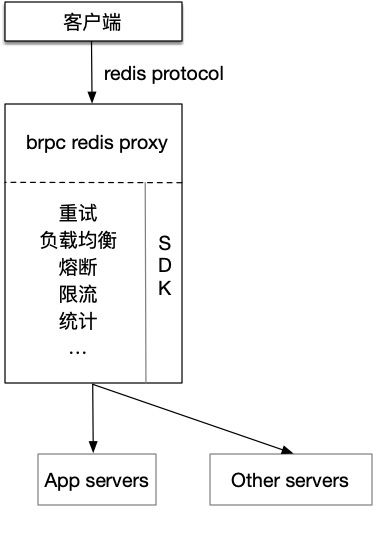
为了更好地理解,这里介绍一个可能的应用场景,在一个分布式key-value系统中的应用。这类系统一般的实现中包含一个metaserver集群,和数据节点集群,如果采取用户通过SDK方式来访问系统,这里做的事情简略来说是先访问metaserver得到数据节点分布等元信息,然后通过某种负载均衡的方式来访问数据节点,如果数据节点访问错误还得做重试,即使节点没挂,也会据业务层的错误码判断是否重试,总之这是一个非常复杂的SDK。如此复杂的SDK还得为每个语言都写一套,很难保证所有语言在某些逻辑上是完全一致的,不仅如此,多套语言的SDK的背后往往意味着巨大的维护成本。
作为解决方案,用brpc写一个redis proxy来做转发,从开发者的角度来说,只需要写一套C++ SDK然后集成到proxy中即可,大大减少了维护的成本和难度。由于SDK的功能全部下沉到了proxy,原来需要业务方升级SDK来支持的功能(如统计上报,改变重试策略等)也可以不依赖于业务方。从系统的用户角度来说,使用新功能的成本大大降低,并且不需要引入一个那么复杂的SDK也保证了程序的正确性和稳定性,SDK使用方式的学习成本也变低了。
在上述的分布式key-value系统的例子中引入了proxy后,还可以玩一些花哨的东西,比如自动缓存。在cache-aside缓存系统里,用户需要和数据库和缓存交互,很容易写出一些竞态的代码[2],而如果将缓存隐藏在proxy后,那么就可以将这部分涉及到更新缓存的代码下沉到proxy,大大减少了业务开发同学的心智负担,只需要像访问单机一样就可以访问缓存+DB的存储系统。
系统设计包含大量的取舍(tradeoff),不会存在一种在每个方面完胜的设计,使用brpc redis proxy也不会是银弹。例如,请求和回复都在proxy上做了一次停留,或多或少会引入延迟,带来一些性能上的消耗。若真的对性能有较高的要求,在部署上可以采取sidecar模式,优点是性能与使用原生SDK几乎是一样的,缺点是依然需要业务方去主动升级,但总比更换SDK方便一些。
总结 在本文中,分析了传统发布SDK的问题,提出了一种在brpc中实现灵活SDK的解决方案,讨论了实现中的取舍,并在一个应用场景中讨论了使用方式和效果。
Reference: [1] https://github.com/apache/incubator-brpc/pull/972 [2] https://coolshell.cn/articles/17416.html
感谢戈君、陈章义对本文的审校。